Structuring a Serverless Data Platform on AWS: A Reusable Blueprint for Lambda and Glue
· 11 min read TL;DR
Serverless on AWS scales beautifully — until your codebase doesn’t. After replacing a legacy data platform with Lambda, Glue, and S3 over the past year, I converged on a blueprint:
- Treat serverless as a platform, not a bag of scripts
- Keep shared utilities (logging, config, error handling) in a versioned
service_coremodule - Package the same shared code differently for Lambda (Layers) and Glue (
--extra-py-files) - Enforce one-way dependencies — microservices import shared code, not the other way around
- Deploy and orchestrate independent services with Serverless Compose
The result: a platform that scales without becoming a monolith. Code lives at github.com/raguvindtharanitharan/aws-data-platform-structure.
The problem nobody talks about
Over the past year, I’ve been replacing a legacy data platform with a serverless architecture on AWS — Lambda, Glue, S3, the now-standard set. The promised benefits showed up: elasticity, lower spend, simpler governance.
What also showed up — and what doesn’t get written about enough — is sprawl. Without deliberate structure, serverless platforms drift fast. We caught ourselves reimplementing the same logger across five Lambda functions, copy-pasting error handling between Glue jobs, embedding configuration into scripts that nobody could maintain three months later. The platform was elastic. The codebase was a mess.
The fix wasn’t tools. It was discipline: treat serverless as a platform, not a bag of scripts. That means versioned shared modules, runtime-aware packaging, and explicit deployment orchestration — the same architectural concerns you’d apply to any production system, just adapted to AWS’s serverless primitives.
This piece is foundational. The patterns here aren’t about AI, agents, or anything “AI-native.” But they’re the prerequisite. You can’t bolt observability, intelligent operations, or agent-driven workflows onto a sprawl of one-off scripts. You have to build the platform before you can make it smart.
What follows: how I structure the repository, how the same shared code gets packaged for Lambda and Glue without forks, and how Serverless Compose ties multi-service deployments into a single, predictable workflow.
Structuring the project
The first decision wasn’t about code. It was about ownership.
A serverless data platform that spans Lambda and Glue can either be organized around jobs and functions (one folder per Lambda, one per Glue script) or around responsibilities (shared logic separated from service-specific logic, with explicit boundaries between them). I picked the second.
Three principles I held to:
- Share and version reusable code. Common utilities — logging, configuration, data access — live in a single
service_coremodule, versioned independently from the services that consume it. - Package once, deploy multiple ways. The same shared module gets packaged differently per runtime: a Lambda Layer for functions, a Glue-compatible ZIP for jobs.
- No bloated scripts. Each Lambda or Glue job stays focused on its responsibility and pulls in only the utilities it needs.
Repository layout
A serverless-compose.yml at the root coordinates deployment of multiple Serverless Framework services. Each major component — service_core and individual microservices — is its own deployable unit:
aws-data-platform-structure/
│
├── build-scripts/ # Helper scripts for build and packaging
│ ├── file-helper.js
│ └── initialize.js
│
├── service_core/ # Core reusable logic and shared modules
│ ├── repositories/
│ │ ├── athena_repository.py
│ │ └── dynamodb_repository.py
│ ├── utils/
│ │ └── logger.py
│ ├── serverless.yml
│ └── .serverless/
│
├── demo-micro_service/ # Independent microservice using core modules
│ ├── lambdas/
│ │ └── hello_world_lambda.py
│ ├── glue_jobs/
│ │ └── hello_world_data_extractor.py
│ ├── serverless.yml
│ └── .serverless/
│
├── serverless-compose.yml # Composition file orchestrating deployments
├── package.json
└── README.mdThe composition file is short, but it’s load-bearing:
# serverless-compose.yml
services:
service-core:
path: ./service_core
demo-micro-service:
path: ./demo-micro_service
dependsOn: service-coredependsOn is the discipline. Shared artifacts get deployed first, services that consume them deploy after. No coordination by hand, no out-of-order failures, no monolithic config file.
Ownership boundaries
The service_core module is intentionally thin. It holds cross-cutting concerns — logging, data access, configuration, error handling — and nothing else. No business logic. No service-specific assumptions. No execution flow tied to specific triggers.
Microservices, by contrast, own their business logic, triggers, workflows, and configuration. They depend on service_core, but service_core never depends on them.
That last sentence is the rule I enforce hardest:
Shared code never depends on consuming services. One-way dependencies, always.
Break this rule and you get circular dependencies, deployment lock-in, and ambiguous ownership. Hold it and shared components evolve deliberately while services remain free to change independently.
Architecture
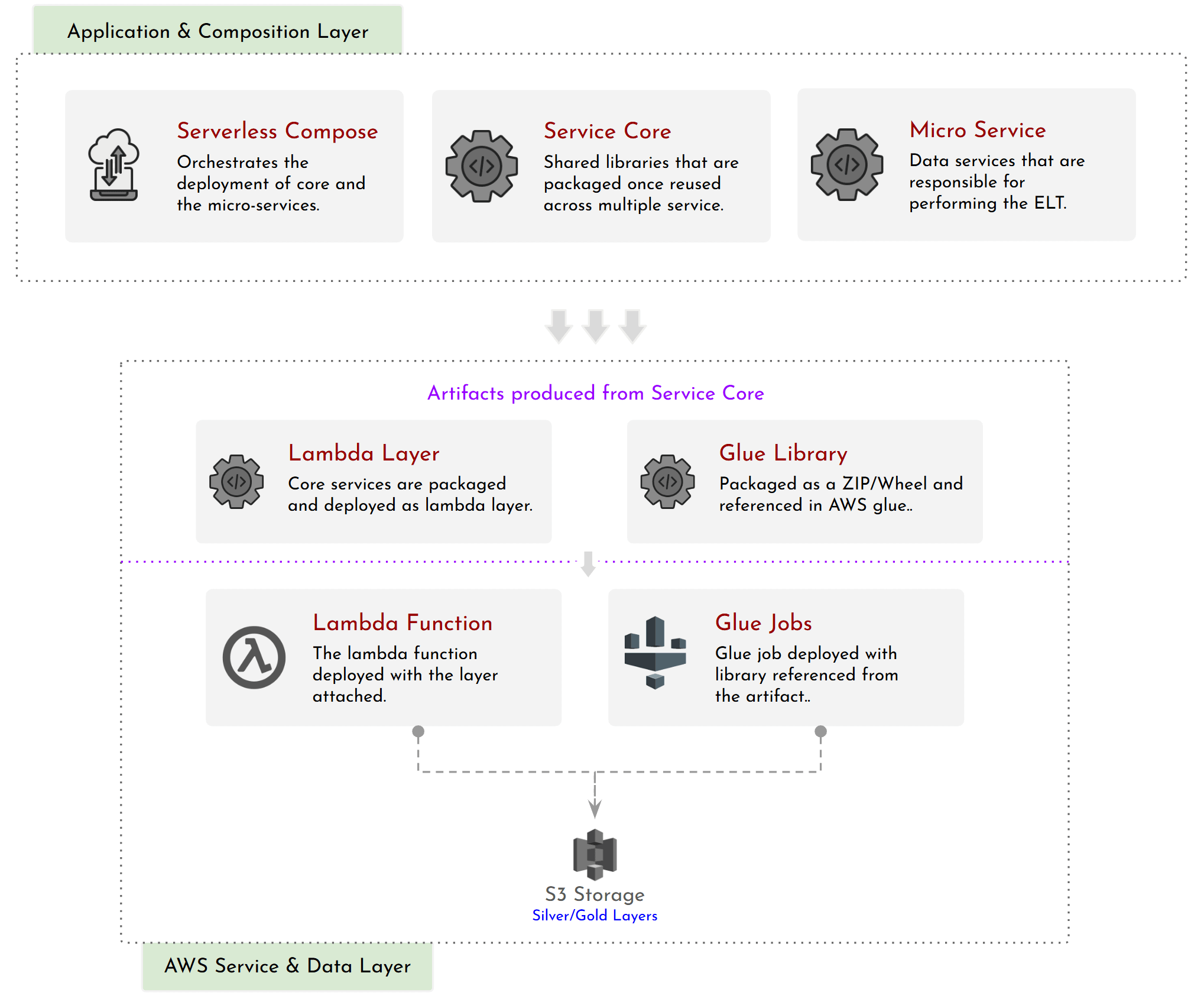
The diagram maps the repository structure onto runtime components. Three layers:
- Application and Composition —
serverless-composeorchestrates deployment ofservice_coreand the microservices. - Shared Core —
service_coreis developed once, never executed directly. It gets packaged into two artifacts: a Lambda Layer for functions, and a Glue library uploaded to S3 for jobs. - Microservices and Data Layer — Lambdas and Glue jobs consume the shared artifacts and write to S3 (Silver/Gold layers in the data lake).
Microservices don’t share code with each other. They share artifacts — versioned, packaged, immutable — produced from a single source of truth.
Scaling across environments
The structure scales cleanly across dev, staging, and production. Each service is independently deployable, environment-specific config is injected at deploy time, and shared components stay identical across environments. New microservices reuse the same versioned core utilities — no duplicated infrastructure, no configuration drift, no resource collisions.
Packaging the same code for Lambda and Glue
This is the part most “serverless data platform” articles skip, and it’s where the blueprint earns its keep.
The constraint: Lambda and Glue have different runtime contracts. Lambda functions have a 250 MB unzipped package limit and prefer Layers for shared dependencies. Glue jobs run on Spark workers and pull additional Python files via the --extra-py-files argument. Same Python, two completely different packaging mechanics.
The temptation is to fork — write the logger once for Lambda, again for Glue, and accept the duplication. That works for two services. It collapses at twenty.
The pattern I use instead: one source, two packagings.
One logger, two artifacts
service_core/utils/logger.py is a single file:
# service_core/utils/logger.py
import json
import logging
import os
class JsonFormatter(logging.Formatter):
def __init__(self, service: str):
super().__init__()
self.service = service
def format(self, record):
return json.dumps({
"level": record.levelname,
"service": self.service,
"message": record.getMessage(),
"module": record.module,
})
def get_logger(name: str, service: str) -> logging.Logger:
logger = logging.getLogger(name)
logger.setLevel(os.getenv("LOG_LEVEL", "INFO"))
handler = logging.StreamHandler()
handler.setFormatter(JsonFormatter(service=service))
logger.addHandler(handler)
return loggerA Lambda function imports it like any normal package, because it’s available via a Layer:
# demo-micro_service/lambdas/hello_world_lambda.py
from service_core.utils.logger import get_logger
logger = get_logger(__name__, service="hello-world")
def handler(event, context):
logger.info(f"received event: {event}")
return {"statusCode": 200, "body": "ok"}A Glue job imports it the same way — but the artifact path is wired in via --extra-py-files:
# demo-micro_service/serverless.yml (Glue job definition excerpt)
resources:
Resources:
HelloWorldGlueJob:
Type: AWS::Glue::Job
Properties:
Name: hello-world-data-extractor
Role: ${self:custom.glueRole}
Command:
Name: glueetl
ScriptLocation: s3://my-glue-scripts/hello_world_data_extractor.py
DefaultArguments:
"--extra-py-files": "s3://my-shared-libs/service_core-1.2.0.zip"
"--service-name": "hello-world"Identical import statement in the job script:
# demo-micro_service/glue_jobs/hello_world_data_extractor.py
from service_core.utils.logger import get_logger
logger = get_logger(__name__, service="hello-world")
logger.info("Glue job starting")
# ... extract / transform / loadThe job code doesn’t know whether it’s running in Lambda or Glue. It just imports service_core and gets a working logger. The packaging — Layer vs. ZIP — is invisible at the import boundary.
Why this matters
Two payoffs:
- No forks. Logging, configuration, error handling — one source of truth, fixed in one place, propagated everywhere on the next deploy.
- Consistent observability. Lambda logs and Glue logs come out of the same
JsonFormatter, with the same fields. CloudWatch queries and downstream log pipelines work uniformly across the platform.
The small build complexity (two packaging steps instead of one) is dwarfed by what it removes: drift, copy-paste, and the silent skew that builds up when teams maintain “the Glue version” of the logger separately from “the Lambda version.”
Orchestrating multi-service deployments
As the platform grew past one or two services, ad-hoc deploys became fragile. Shared artifacts had to exist before consumers. Order mattered. Manual coordination was a recipe for half-broken environments.
Serverless Compose solved this. Each component — service_core, each microservice — stays an independent Serverless Framework service. The composition file at the repo root defines the dependency graph:
services:
service-core:
path: ./service_core
hello-world:
path: ./demo-micro_service
dependsOn: service-coreA single command — serverless deploy from the root — walks the graph and deploys in order. If service-core hasn’t changed, it’s a no-op; if a microservice has changed, only that microservice redeploys.
What this gave me:
- Deterministic order. Shared artifacts are always present before consumers try to use them.
- One entry point for full or partial deployments.
- Clear isolation. Services have their own lifecycle without a monolithic config swallowing everything.
As new microservices got added, deployments stayed predictable. No “we forgot to deploy service-core first” Slack threads.
What this discipline buys you operationally
When the structure holds, the operational profile gets noticeably better.
Lambda handlers shrink to orchestration: validate inputs, call shared utilities, coordinate downstream services. Glue jobs shrink to data transformation: extract, transform, write — with logging, config, and data access delegated to service_core.
Because every service uses the same shared components:
- Logs follow a consistent structure across Lambda and Glue. Querying CloudWatch by service or error level just works — no per-service field translation.
- Configuration loads and validates uniformly. The same
get_config(env)returns the same shape everywhere. - Debugging requires less context-switching. You’re reading the same primitives in every service, even if the business logic differs.
When you need to improve something — better log fields, faster config loading, sturdier retry logic — you fix it once in service_core, redeploy, and every service inherits the change on its next deploy. No coordinated PR across twenty repos.
Patterns I’ve stopped using
Five patterns that look fine at three services and fall apart at twenty:
- Copying shared utilities into individual services. Faster on Monday, maintenance disaster by Thursday.
- Embedding infrastructure concerns into Glue scripts or Lambda handlers. Mix them and you can’t change one without touching the other.
- Letting shared code reach back into service-specific behavior. The moment
service_coreknows abouthello_world_lambda, you’ve created a circular dependency that will haunt every deploy. - Treating Glue jobs as one-off scripts instead of deployable services. A Glue job is production code. Treat it like Python you’d put in production: version control, package management, code review, deploy pipeline.
- Designing data services as if AI agents will never touch them. The foundation you build now determines what’s possible later. A platform that’s fragmented across forks and one-off scripts is a platform that can’t be observed, queried, or operated on by anything — human or otherwise.
Why this scales over time
This structure scales because it aligns with how serverless platforms actually evolve.
New services arrive and reuse the existing shared components instead of reimplementing baseline functionality. Shared code is versioned and deployed independently — core capabilities improve without forcing coordinated changes across every service. Microservices stay isolated, with clear ownership and minimal coupling.
And — most importantly — the platform stays legible. New engineers can reason about where code lives, how it’s deployed, and how services interact without tracing duplicated logic across dozens of functions and jobs. Legibility is an underrated property in production systems; it compounds.
What’s next
Moving to a serverless data platform unlocked scalability and cost benefits. Those gains only materialized once shared code was treated as a first-class component — packaged, versioned, deployed with the same discipline as any other production system.
What I’m exploring next: how to make these workloads not just structured, but operable — observable, callable, and safe to act on by automation and AI agents. The structure described here is the foundation. The next layer is making it intelligent.
Future posts will work through:
- Production-grade logging and structured events for serverless workloads
- Configuration management across Lambda and Glue (without environment-variable sprawl)
- CI/CD patterns for multi-service serverless platforms
- And eventually: making serverless data platforms agent-friendly — what observability, callability, and safety look like when AI agents are expected to operate on them
Code: github.com/raguvindtharanitharan/aws-data-platform-structure