The Investigation Layer: what the modern data stack is still missing
· 6 min read TL;DR
Modern data platforms are very good at detecting failures — but far worse at explaining what those failures actually mean. This article introduces the Investigation Layer: the operational bridge between technical alerts and business understanding.
Using two real freshness alerts with identical errors but opposite operational responses, we explore:
- Why monitoring alone is insufficient in modern DataOps
- The difference between technical failures and business impact
- Why investigation is still mostly manual in modern data stacks
- How AI-era systems increase the cost of operational misunderstanding
- Why the modern DataOps stack is evolving beyond observability into operational reasoning

Monitoring tells you something failed. The Investigation Layer explains:
- why it failed,
- what is impacted,
- whether the business should care, and what should happen next.
When the Alert Fires
The alert came in at 2:04am. Two tables flagged with the same stale_error.
$ dbt source freshness
02:04:23 ERROR freshness of raw.stores
02:04:25 ERROR freshness of raw.ordersSame alert. Same severity.
Someone now has to decide:
wake a person up, or let it ride until morning?
That decision sounds simple until you realize the monitoring system can’t actually answer the question that matters:
What does this alert mean operationally?
So the investigation starts.
First table: stores.
select
count(*) as row_count,
max(_loaded_at) as last_loaded
from raw.stores;Result:
6 rows
last updated: September 2019At first glance, this looks catastrophic. A table stale for six years should mean a completely broken pipeline.
Except it doesn’t.
The company has six physical store locations. That table only changes when a store opens or closes. It’s a reference table. It’s supposed to be stable.
The pipeline is fine.
The alert is wrong.
Second table: orders.
select
count(*) as row_count,
max(_loaded_at) as last_loaded
from raw.orders;Result:
61,948 rows
last updated: 277 days agoCompletely different situation.
This table ingests transactional order data continuously throughout the day. There should be fresh records every few hours. The pipeline has actually stalled.
Now someone should absolutely get paged.
Same alert. Opposite operational responses.
And this is the part modern data tooling still handles poorly.
Monitoring systems are very good at detecting threshold breaches. They can tell you a table is stale, a model failed, or a schema drifted.
But they usually cannot tell you:
- whether the issue matters,
- what broke upstream,
- which systems are affected,
- how urgent the problem is,
- or whether this is an actual incident versus operational noise.
That work still happens manually.
An engineer opens lineage graphs. Someone checks Airflow runs. Another person starts querying the warehouse directly. Slack threads appear. People compare timestamps across systems trying to reconstruct context from fragments spread across monitoring tools, orchestration systems, warehouses, and tribal knowledge.
That process is investigation.
And despite how modern the data stack has become, most organizations still treat investigation as an informal human skill instead of a real architectural layer.
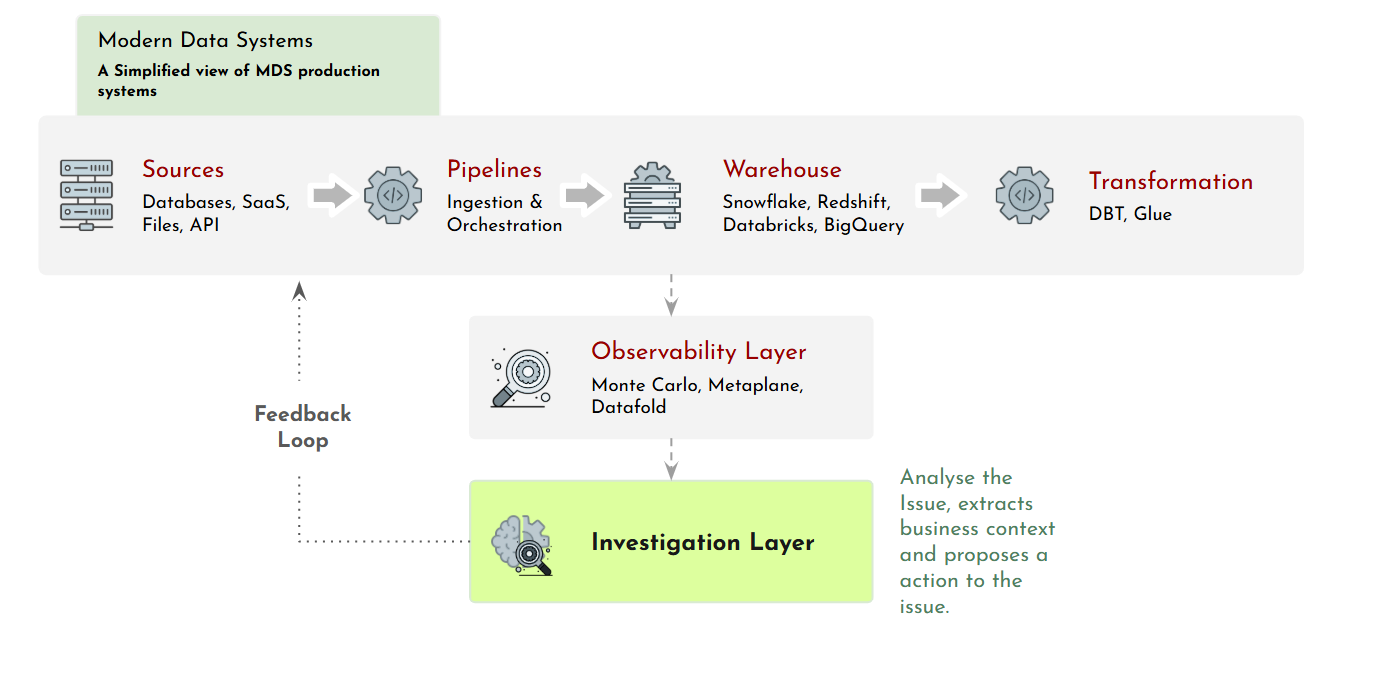
The Investigation Layer
Most modern data stacks already have mature infrastructure layers:
Sources → Pipelines → Warehouses → Transformations → MonitoringBut once monitoring detects a failure, there’s still a missing step between the alert itself and an informed operational response.
That missing step is the Investigation Layer.
Technical Signals
↓
Investigation Layer
↓
Business Context
↓
Actions / ResponsesMonitoring surfaces technical signals.
The Investigation Layer turns those signals into operational understanding.
That includes:
- lineage tracing,
- root cause analysis,
- blast-radius analysis,
- business criticality,
- alert correlation,
- prioritization,
- and operational recommendations.
In practice, this is the layer that answers questions like:
- Is this customer-facing?
- Is the data actually wrong?
- Which dashboards or AI systems are affected?
- Should someone be paged?
- What should happen next?
The important thing here is that these are not infrastructure questions anymore.
They are operational reasoning questions.
Why This Matters More Now
For years, bad data mostly meant:
- broken dashboards,
- incorrect reports,
- or annoyed analysts.
That world is changing.
Modern data platforms now feed:
- operational automations,
- recommendation systems,
- forecasting models,
- AI agents,
- LLM applications,
- and real-time decision systems.
Data is no longer passive infrastructure.
It is becoming an active operational dependency.
And that changes the cost of misunderstanding a signal.
A stale dashboard is inconvenient.
A stale operational system making autonomous decisions from bad upstream data is something else entirely.
That is why the Investigation Layer matters more in the AI era than it did before.
The problem is no longer just detecting failures.
The problem is understanding them fast enough to make the right operational decision before downstream systems react to them.
This Is a Practice
The person who looked at those two alerts and immediately knew one was noise and the other was a real incident was not guessing.
They were applying operational judgment built from experience: understanding dataset semantics, recognizing business criticality, tracing lineage mentally, and interpreting technical signals in operational context.
That skill exists in almost every mature data organization.
But most teams still treat it as tribal knowledge instead of a real discipline.
The investigation process usually lives in undocumented habits, old Slack threads, and the instincts of whichever engineer happens to know the system best. New engineers learn it informally over time. Senior engineers become operational bottlenecks because too much context exists only in their heads.
But this work is not accidental.
It is a repeatable operational practice.
It has workflows, heuristics, prioritization patterns, escalation logic, and reasoning steps that experienced practitioners execute every day — even if nobody has formally named it yet.
That practice is the Investigation Layer.
And the more operational and AI-driven modern data systems become, the more important it is to treat investigation as a real discipline instead of an invisible skill.
The orders table needed an engineer immediately. The stores table needed a monitoring config review sometime in the last six years.
Most teams treat those as the same problem.
The ones that don’t have already built the Investigation Layer — even if they don’t call it that yet.