PromptOps: The DataOps Playbook for Prompts
· 10 min read TL;DR
Prompts are the most ungoverned operational asset in modern AI systems — and we’re about to repeat every governance mistake the data world spent twenty years correcting. The fix:
- Treat prompts as first-class versioned assets — metadata, ownership, lineage
- Build a prompt registry as the single source of truth (mirrors a data catalog)
- Apply DataOps discipline: validation, CI/CD, drift detection, observability
- Wire prompt governance into the platform — not as a tool bolted on, as a layer of the architecture
I’m calling this PromptOps. It’s not a new idea; it’s the DataOps playbook applied to a layer most teams haven’t realized needs it yet.
A follow-up post covers the implementation in detail — directory structure, CI/CD pipeline, CloudWatch metrics, drift evaluation. This piece is the architectural argument.
The next layer nobody is governing
I’ve spent twenty years watching organizations slowly tame their data. Disorderly data into governed lakes. Manual provisioning into Infrastructure as Code. Wild model experiments into MLOps. Each generation of discipline took years to standardize and another decade to enforce.
We’re standing at the start of the next loop, and almost nobody is paying attention.
Prompts are showing up everywhere — embedded in production code, scattered across notebooks, copy-pasted between tools, owned by no one. Business decisions are being made by AI systems whose instructions live in someone’s last Slack message. The prompt has become a critical operational asset, and we’re managing it the way teams managed SQL queries in 2008: in scripts, in chat, in people’s heads.
In the previous piece, I argued that serverless data platforms don’t earn their keep until you treat them as platforms — versioned shared modules, deliberate boundaries, packaged once and consumed by multiple runtimes. The argument here is the same one, applied to a new layer: prompts are data assets, and the entire DataOps playbook ports over. I’m calling the result PromptOps.
The patterns aren’t new. The application is. What follows is the playbook — four tenets, six layers of architecture, and the anti-patterns to avoid.
The chaos of unmanaged prompts
Walk into a typical organization building production AI systems and look at where the prompts live. You’ll find:
- Prompts pasted directly into Lambda function code
- Prompts in
.envfiles getting copied between environments - Prompts in Confluence pages someone last edited eight months ago
- Critical business decisions resting on a piece of text owned by no one
Three failure modes show up reliably:
- No lineage. A model’s behavior changes overnight. Was it the model? The fine-tune? The prompt? Nobody can tell — because the prompt that was running yesterday isn’t recorded anywhere.
- No ownership. A prompt drives a customer-facing feature. Three engineers have edited it. None of them remember what changed or why.
- No reproducibility. A regression hits prod. Rolling back the deploy doesn’t fix it — because the prompt isn’t versioned with the deploy.
The data world had every one of these failure modes in 2010, and they didn’t go away until governance became architectural. The same correction is coming for prompts. The teams that get there early will look like they had foresight; the teams that don’t will spend a year explaining outages.
PromptOps closes the gap by making the prompt layer an explicit, governed, observable concern — not a side artifact.
DataOps → MLOps → PromptOps
Each operational discipline solved a specific governance gap in its time:
- DataOps — governs how data moves through pipelines. Versioned schemas, lineage, observability, contracts at boundaries.
- MLOps — governs how models train, deploy, and degrade. Reproducible training runs, deployment pipelines, monitoring for drift.
- PromptOps — governs how instructions to models move through systems. Versioned prompts, registry, evaluation, drift detection.
The shape is identical. The asset class changes, but the architectural principles — versioning, lineage, validation, observability — are the same. Anyone who has built a DataOps pipeline already understands 80% of PromptOps. The remaining 20% is adapting the discipline to the new asset.
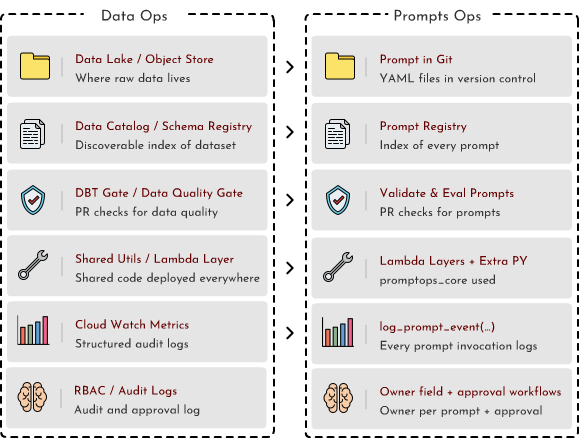
Four tenets of prompt architecture
A PromptOps platform stands on four core capabilities. Each maps cleanly to a familiar DataOps equivalent:
1. Prompt inventory
A centralized registry capturing every prompt in production: its purpose, owner, model, version, dependencies, and metrics. Same idea as a data catalog or a metric layer — the registry is the single source of truth, and everything else (Lambda, Glue, SDKs) consumes from it.
A minimal entry looks like this:
id: customer-support.intent-classifier
version: 2
owner: data-platform-team
model: claude-3-5-sonnet
parent: 1 # version lineage
tags: [classification, customer-support]
metrics:
baseline_accuracy: 0.94
cost_per_call_usd: 0.003
template: |
You are a customer support intent classifier. Given the user
message and the previous conversation context, classify the
intent into one of: billing, technical, sales, retention, other.
...
created: 2026-04-15
updated: 2026-05-01Note what isn’t optional: ID, version, owner, model, lineage. The registry rejects any prompt missing these. If you can’t write down who owns a prompt, you don’t yet have a prompt — you have a guess.
2. Versioning
Prompts get versioned the way schemas get versioned. Every meaningful change — tone shift, constraint change, compliance update — is a new version with a parent reference. Old versions stay accessible. Deployments pin to a specific version, not “latest.”
This is the mechanic that makes lineage tractable. When a model output changes, you can trace it back to the exact prompt version that produced it — the same way you trace a data anomaly back to a specific transformation.
3. Testing and validation
Every prompt change gets validated before deploy. The validation suite covers two layers:
- Static — schema check (required fields present, version is an integer, owner is a real team)
- Behavioral — runs the new prompt against a held-out evaluation set, compares against the previous version on the metrics declared in the prompt’s own metadata
This is the equivalent of running data quality checks on a new pipeline before it ships. A failed eval blocks the merge:
"""Run on every PR: blocks merge if any prompt is missing required metadata."""
import sys
import yaml
from pathlib import Path
REQUIRED = {"id", "version", "owner", "model", "template", "tags"}
def validate(path: Path) -> list[str]:
data = yaml.safe_load(path.read_text())
errors = []
missing = REQUIRED - set(data.keys())
if missing:
errors.append(f"{path}: missing required fields {missing}")
if not data.get("template", "").strip():
errors.append(f"{path}: empty template")
if not isinstance(data.get("version"), int):
errors.append(f"{path}: version must be an integer")
return errors
if __name__ == "__main__":
all_errors = []
for prompt_path in Path("prompts").rglob("*.yaml"):
all_errors.extend(validate(prompt_path))
if all_errors:
print("\n".join(all_errors))
sys.exit(1)
print("All prompts valid")This script does what every team wishes their codebase already had: forces ownership, blocks orphan prompts, makes governance the path of least resistance. The behavioral evaluation hook (not shown) extends this with model calls and metric comparisons against the baseline.
4. Monitoring and drift detection
Once deployed, prompts get monitored the same way data pipelines do — but for behavioral, not structural, drift:
- Response variance — distribution of outputs over time. Sudden shifts trigger alerts.
- Cost drift — token usage per call. If average cost climbs 15% over a week without a prompt change, something upstream is feeding longer context.
- Quality drift — periodic re-runs of the eval suite against live prompts. Compared against the baseline metrics declared in metadata.
Each maps directly to existing data observability primitives. CloudWatch metrics, Athena queries, alerting — same tooling, new asset class.
The PromptOps stack
A working PromptOps platform isn’t a product. It’s a stack of layers that mirrors how data platforms are organized:
| # | Layer | What it does | DataOps equivalent |
|---|---|---|---|
| 1 | Storage | Prompts as versioned files in Git or object store. Source of truth lives here. | Data lake / object store |
| 2 | Registry | API or library that loads prompts by ID + version, validates schema, returns immutable assets | Data catalog / schema registry |
| 3 | CI/CD | Validation gate on every PR — schema, evaluation, drift. Blocks merge on failure. | Data quality gate / dbt build |
| 4 | Runtime | Loader library shared across services (Lambda, Glue, agents). One import path, all runtimes. | Shared utilities / Lambda Layer |
| 5 | Observability | Logs every prompt invocation: prompt ID, version, latency, tokens, cost, model. Feeds dashboards. | CloudWatch metrics / pipeline observability |
| 6 | Governance | Ownership records, approval workflows for sensitive prompts (legal/compliance), audit trail | RBAC / audit logging |
Most teams today have zero of these layers. The ones that do have a layer or two — usually a Git repo of prompts and ad-hoc loading code — but lack the rest. The point of an architecture isn’t that you build all six on day one. The point is that you know all six exist and decide deliberately which to invest in next.
The runtime layer is the one I’ve found pays for itself fastest: a single shared loader library used across all services means prompts get versioned consistently, observability is uniform, and changes propagate without per-service edits. It’s the same Lambda Layer + Glue ZIP pattern from the previous piece, applied one layer up the stack:
from dataclasses import dataclass
from pathlib import Path
import yaml
PROMPTS_DIR = Path(__file__).parent.parent.parent / "prompts"
@dataclass
class Prompt:
id: str
version: int
owner: str
model: str
template: str
tags: list[str]
def load_prompt(prompt_id: str) -> Prompt:
"""Load a prompt by ID. Same import path in Lambda or Glue."""
path = PROMPTS_DIR / f"{prompt_id.replace('.', '/')}.yaml"
data = yaml.safe_load(path.read_text())
return Prompt(
id=data["id"],
version=data["version"],
owner=data["owner"],
model=data["model"],
template=data["template"],
tags=data.get("tags", []),
)The job code doesn’t care whether it’s running in Lambda or Glue. Same import, same shape, same governance. Versioning becomes a deploy-time concern, not a runtime one.
Patterns I’ve stopped accepting
The same shortcut patterns that wrecked early data platforms are showing up in early prompt platforms. Five I won’t tolerate anymore:
- Inline prompts in business logic. A prompt embedded in a Lambda handler is a configuration value pretending to be code. It can’t be versioned independently, can’t be reused, can’t be rolled back without a deploy.
- Owner-less prompts. If no team owns it, no team will fix it when it breaks.
- No version pinning. Deploying with “the latest prompt” makes prod behavior non-reproducible. Pin every consumer to a specific version.
- Prompt evals as an afterthought. If you wouldn’t ship a SQL pipeline without data quality checks, don’t ship a prompt without behavioral checks.
- Prompt logs in the same fire hose as everything else. Prompt invocations need their own structured logs (id, version, tokens, latency at minimum). Searching CloudWatch for “what prompt produced this output” needs to take seconds, not hours.
What’s next
This piece is the playbook. The next one is the implementation: directory structure, GitHub Actions wired to behavioral evals, CloudWatch dashboards for prompt observability, and the drift detection metric in detail.
I’m also exploring how PromptOps becomes the substrate for agent-driven systems — where prompts aren’t called by humans but composed and executed by autonomous agents. The governance discipline is the same. The volume is two orders of magnitude higher. Most teams aren’t ready for that yet, and the few that are will look unbeatable in 18 months.
Build the platform first. Then make it smart.
Code: Reference implementation coming with the next post — separate repo, link added when published.